GPU Research & Development
At ICHEC we carry out cutting-edge Research & Development on several GPGPU architectures, including NVIDIA's Tesla range of GPUs.
Much of our R&D on GPGPUs is carried out within ICHEC's CUDA Research Centre (CRC) and is driven by both national and international collaborative projects including the European PRACE research infrastructure, EU Horizon 2020 projects and ICHEC's Industry Services Program.
ICHEC is widely recognised for its expertise in enabling applications on GPU platforms and was awarded the prestigious HPCWire Readers Choice Award 2012 for 'Most Innovative Use of HPC in Financial Services'. (You can find out more about this work here)
As part of GPGPU R&D activities ICHEC is pursuing the following goals:
- To port codes that are of major interests to Irish academia and industry to take advantage of GPGPUs.
- To build a strong pool of expertise in the field that empowers ICHEC to advise and support users who wish to evaluate GPU computing themselves.
- To build partnerships - with manufacturers, developers and users communities - that enable access to new hardware, codes and tools for the Irish community.
ICHEC has invested considerable effort to ensure that emerging technologies in GPGPUs can be effectively exploited. The expertise we have gained on both older and current hardware platforms will be beneficial in this regard, as well as for projects which will require access to large installations with GPUs, e.g. those in PRACE.
Previously Funded Research Projects
Below, you can find brief descriptions of the publicly funded GPGPU Research projects that ICHEC is currently involved in.
Investigating Performance Benefits from OpenACC Kernel Directives
OpenACC is a programming standard for parallel computing developed by Cray, CAPS, Nvidia and PGI. The standard is designed to simplify parallel programming of heterogeneous CPU/GPU systems. Like in OpenMP, the programmer can annotate C, C++ and Fortran source code to identify the areas that should be accelerated using PRAGMA compiler directives and additional functions. Unlike OpenMP, code can be started not only on the CPU, but also on the GPU.
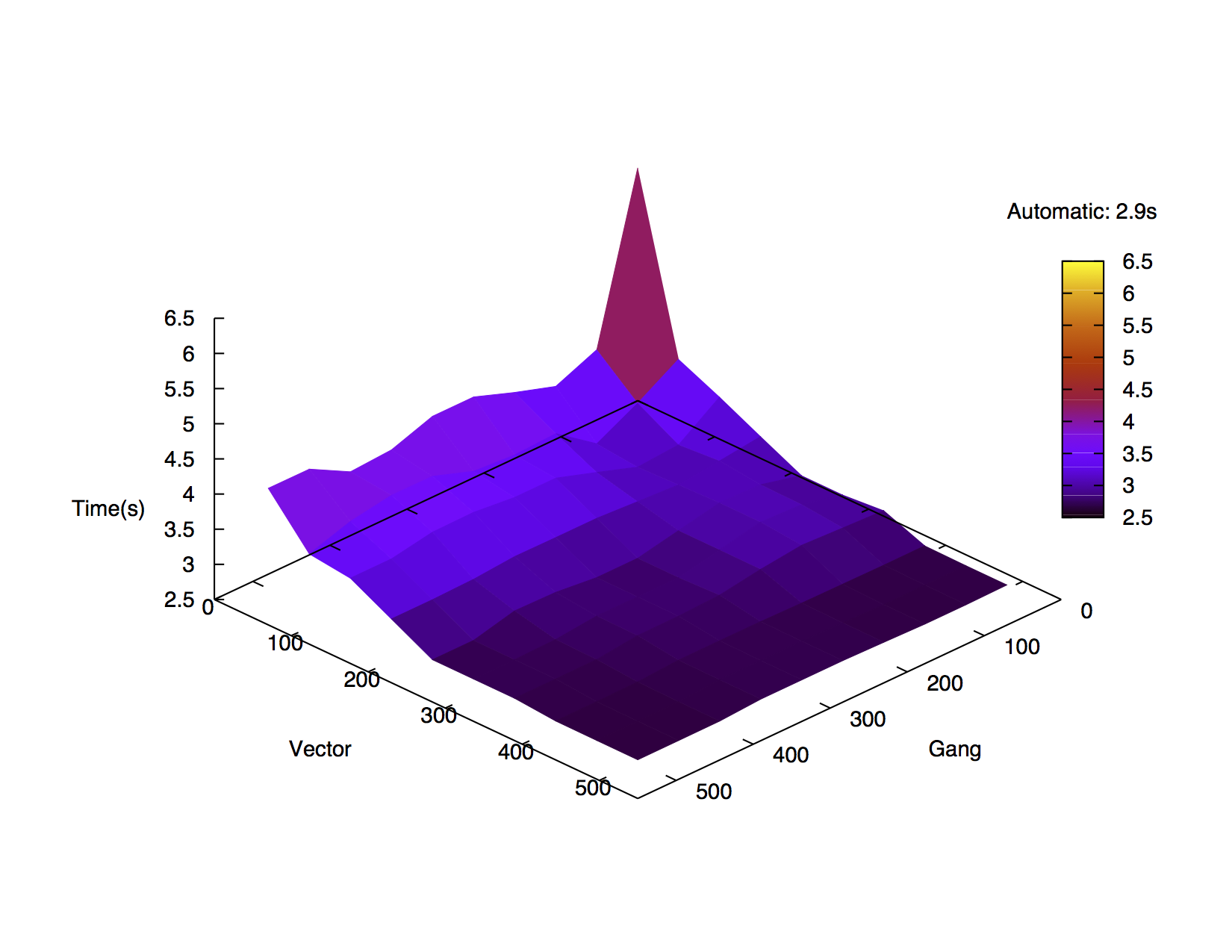
CGS runtime results for various gang and vector sizes compiled using CAPS (above) and PGI (below) compilers and run on an M2090 GPU.
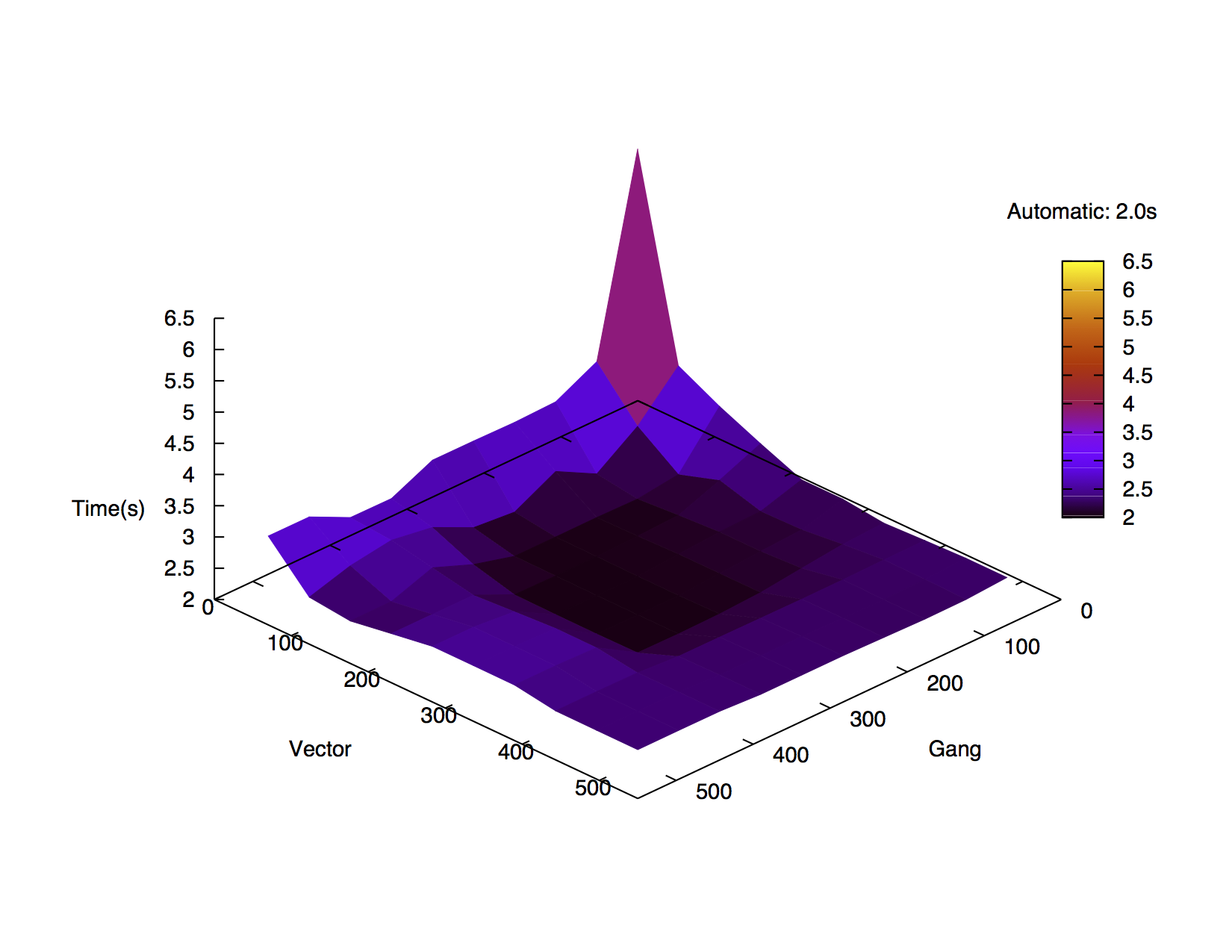
ICHEC’s staff investigated the possible benefit of using OpenACC performance tuning directives, comparing the two prevalent implementations of the standard, CAPS and PGI. The performance of the default generated code along with the impact of the gang and vector parameters is being evaluated through a matrix-matrix multiplication algorithm and a Classical Gram-Schmidt orthonormalisation algorithm. Additionally, the impact of these directives in the context of a change in hardware is being investigated.
Funded by:
This research was funded by the European PRACE 2IP project.
Autotuning For Current GPU-based Platforms
The increasing complexity of parallel architectures for HPC makes it extremely difficult to develop programs that exploit the full capability of the hardware. Application developers have to go through several cycles of program analysis and tuning after code is written and debugged. Thus, the development process has become cumbersome and unveils a huge productivity gap. While some tools aid the developers on performance analysis, no tool supports the code tuning stage.
The Challenges of Programming Parallel Architectures that the Autotune Project addressed.
The AutoTune project’s goal was to develop an extensible tuning environment that automates the application tuning process. The framework, named the Periscope Tuning Framework (PTF), identifies tuning recommendations in special application tuning runs, using plugins for performance and energy efficiency tuning of parallel codes for multicore and manycore architectures. The tuning recommendations generated by PTF can then be manually or automatically applied to optimize the code for later production runs.
ICHEC's role in the AutoTune project mainly concerned the evaluation and assessment of the framework, the tuning techniques and plugins, directing the project's efforts on risk management, progress monitoring and quality control. ICHEC also actively worked on the dissemination and outreach activities, publicising the project's accomplishments and breakthroughs at relevant academic and industrial channels.
Funded by:
This research was funded under the EU's FP7 project, Grant No. 288038, and comprises a consortium of three universities, two supercomputing centres and a leading ISV.
Associated publications/Proceedings:
Autotune: A Plugin-Driven Approach to the Automatic Tuning of Parallel Applications, R Miceli, G Civario, A Sikora, E César, M Gerndt, H Haitof, C Navarrete, S Benkner, M Sandriesser, L Morin, F Bodin, Proceedings of the 11th International Workshop on State-of-the-Art in Scientific and Parallel Computing (PARA 2012), pp328-342 (under publication at Springer LNCS volume 7782; to be published in February 2013).
Future Proofing the Irish Weather Forecasting software package, Harmonie, for large-scale GPU-based Platforms
Harmonie is the numerical weather prediction system used by Met Éireann (and a wider consortium of mostly northern-European countries) to make detailed short-term weather forecasts (out to about 3 days) for Ireland. It is the most detailed and most localized of the hierarchy of models that are used to predict the weather out to approximately two weeks.
The only practical way to use GPUs to accelerate a complex package like Harmonie is by means of OpenACC directives, in much the same way that OpenMP directives are currently used for shared-memory parallelism.
Two high-profile routines have initially been selected for acceleration: one from the radiation physics section of Harmonie, the other from the semi-Lagrangian dynamics. Initial results show modest speed up for over a single CPU core using a relatively small model domain over a 24hr forecast. ICHEC plans to expand its investigations to several other subroutines that could be targeted for acceleration, which would reduce the overall execution time of Harmonie.
Funded by:
This research was funded by the Irish EPA under grant number CCRP-09-FS-5-2.
Enabling the Quantum Collisions package, PRMAT, on GPU-based platforms
Electron atom and electron ion collision cross sections are of crucial importance in the analysis of many laboratory and astrophysical plasmas including those arising in laser-plasma interactions, controlled thermonuclear fusion devices such as tokamaks, planetary atmospheres, stellar atmospheres, gaseous nebulae, active galactic nuclei and supernovae.
Over the last twenty-five years a suite of programs based on the R-matrix method have enabled vast amounts of accurate electron collision and opacity data to be calculated by international collaborations, which have had very wide applications. However, in spite of this success, many outstanding problems of importance cannot be treated by these programs which were designed to run on scalar and vector processors. As a result, a completely new parallel program PRMAT has been developed at UK STFC’s Daresbury Laboratory, which is enabling a new class of electron collision problems, involving many hundreds of coupled target states, to be solved for the first time.
ICHEC staff are working in close collaboration with the STFC’s Advanced Computing Group to port PRMAT to large-scale GPU-based platforms and have already demonstrated ~3X speedup of overall application runtime across several hundreds of compute nodes when running the application on 2 GPUs per node.
Funded by:
This research was funded under the EU's PRACE 2IP project.
Enabling the Molecular Dynamics application, DL_POLY, on GPU-based platforms
DL_POLY is a well known molecular dynamics simulation code developed by STFC Daresbury Laboratory in the UK. As part of a collaborative research programme with Daresbury Labs, ICHEC enabled DL_POLY version 3.10 to CUDA. Much of this work was originally carried out by former ICHEC staff member, Christos Kartsaklis, in close collaboration with Dr. Ilian Todorov and Prof. Bill Smith from Daresbury. ICHEC staff have recently updated the CUDA port to enable DL_POLY 4 on the newest generation of NVIDIA GPUs and continue to investigate ways of optimizing performance and porting new algorithms within DL_POLY to GPUs.
The code runs efficiently with a speed-up of around 4x for certain test cases. Furthermore, the code is parallelised with a mix of MPI, OpenMP and CUDA, allowing an efficient usage of both the CPUs and the GPUs of a HPC cluster.
ICHEC computational scientist, Gilles Civario, presented a summary of the work on this port at the prestigious NVIDIA GPU Technology Conference 2010. This presentation can be downloaded from NVIDIA's web site as a FLV file or a MP4 file.
The CUDA-enabled port of DL_POLY has been released as part of the official distribution of DL_POLY_4, which is available for download from Daresbury Laboratory.
Funded by:
This research was funded under the EU's PRACE project.
Associated publications/Proceedings:
This work has been described in a paper entitled "DL_POLY 3: Hybrid CUDA/OpenMP porting of the non-bonded force-field for two-body systems" and was presented by Christos Kartsaklis at the 240th American Chemical Society National Meeting in Boston (22nd-26th August, 2010).
Benchmarking and Analysis of DL_POLY 4 on GPU Clusters, M Lysaght, M Uchroński, A Kwiecien, M Gebarowski P Nash, I Girotto and I T Todorov, PRACE Whitpaper
Previous Commercially Funded Research Projects
Below, you can find brief descriptions of some of the commercially funded GPGPU research projects that ICHEC has recently been involved in.
Real-Time Risk Simulation: Profit Margin Analysis on GPUs
As part of ICHEC’s Technology Transfer Programme, ICHEC staff members, Gilles Civario and Renato Miceli, recently enabled a London-based, world-leading financial services company to dramatically speed-up and improve the quality of its real-time risk management tool chain. Gilles and Renato utilised the latest GPU accelerator hardware and software from NVIDIA to carry out over 1,000 times more computations than was previously possible leading to 30x more precise results.
This research work has recently received widespread recognition from the HPC community with ICHEC staff members, Gilles Civario and Renato Miceli, recently being awarded the prestigious HPCWire Reader’s Choice Award 2012 at SC12 for the ‘Most Innovative Use of HPC in Financial Services’. (You can find out more about this work here)
Funded by:
This work was commercially funded through ICHEC's Technology Transfer Programme.
Associated publications/Proceedings:
Real-Time Risk Simulation: The GPU Revolution In Profit Margin Analysis, G Civario and R Miceli, Session at NVIDIA GPU Technology Conference 2012 (GTC 2012). San Jose, USA. May 2012 Link: pdf slides
Previous Publicly Funded Research Projects
Below, you can find brief descriptions of some of the publicly funded GPGPU research projects that ICHEC has recently been involved in.
PhiGEMM: A Hybrid DGEMM Library For Heterogeneous Platforms
Excellent performance and scalability can be achieved for some problems using hybrid combinations of multiple GPUs and CPU computing resources. Former ICHEC staff members, Filippo Spiga and Ivan Girotto developed a DGEMM BLAS-like library called phiGEMM that can exploit both CPU and GPU architectures using hybrid programming techniques. The library can be called from applications through all standard GEMM interfaces and it is able to perform matrix-matrix multiplications using one or more GPUs as well as the host multi-core processor. An 8.9-times speedup is reported in overall run-time of a representative AUSURF112 benchmark for a PWscf calculation.
Associated publications/Proceedings:
F Spiga and I Girotto, Parallel, Distributed and Network-Based Processing (PDP), 2012 20th Euromicro International Conference on Computing & Processing (Hardware/Software), pp 368-375
Quantum Espresso GPU Porting
ICHEC collaborated with the CNR DEMOCRITOS Group in a feasibility study of porting Quantum Espresso to GPGPU architectures. Two parts of this integrated suite of codes - for electronic-structure calculations and materials modeling at the nanoscale level - are being examined in parallel by two different groups.
Former ICHEC staff members Ivan Girotto and Filippo Spiga worked on porting the PWscf part of the package to GPUs using CUDA.
A Java Library for the Generation and Scheduling of PTX Assembly
ICHEC computational scientists Christos Kartsaklis and Gilles Civario have developed a tool called JASM, introduced at the prestigious NVIDIA GTC 2009 NVIDIA GPU Technology Conference 2009 where Christos presented a talk which discussed ongoing progress regarding the development of a Java-based library for rapid kernel prototyping in NVIDIA PTX and PTX instruction scheduling. It is aimed at developers seeking total control of emitted PTX, highly parametric emission of, and tuneable instruction reordering. It is primarily used for code development at ICHEC but is also expected that the NVIDIA GPU community will also find it beneficial.
GPGPU Optimisation of the Weather Research and Forecasting (WRF) model
As part of a collaboration with the Irish Climate Analysis and Research Units (ICARUS) at Maynooth University, Nicola McDonnell was involved in the implementation of the physics kernel of WRF on the Stoney system where 48 NVIDIA Tesla M2090 cards are installed.
